CUDA SharedMemeory
Cuda Memory Model
Cuda에서 메모리는 크게 Host, Device로 나뉜다.
Host는 Cuda를 호출하는 기기, 윈도우 환경에서는 PC의 메모리 공간을 Host 메모리라고 하고, Cuda가 동작하는 Nvidia 기기, GPU를 Device 메모리라고 한다.
Device 메모리에 대한 정리는 이전에 한번 정리를 했기에 링크로 대체한다.
Shared Memory
최근 프로젝트에서 Adaptive Threshold를 사용 할 일이 있었고, NPP 함수를 이용하여 적용 하였다.
하지만 Adaptive Threshold를 직접 컨트롤해야하는 사양이 생겨 Adaptive Threshold를 직접 작성하여 제어 하였다.
동작은 잘 되었으나 역시 속도가 문제가 되었다.
기존 코드는 텍스쳐 메모리(Source Image)를 BlockSize만큼 각 스레드가 접근하여 평균을 취하는 방식이었다.
여기서 문제는 3x3크기의 BlockSize라고 할 때, 이웃한 스레드가 메모리를 중복 접근하여 성능 손실이 있다는 점이다.
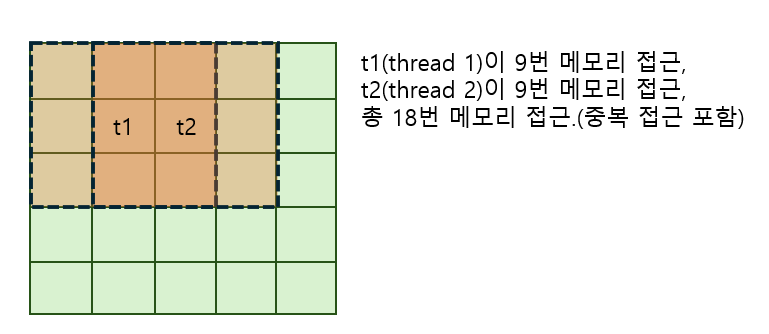
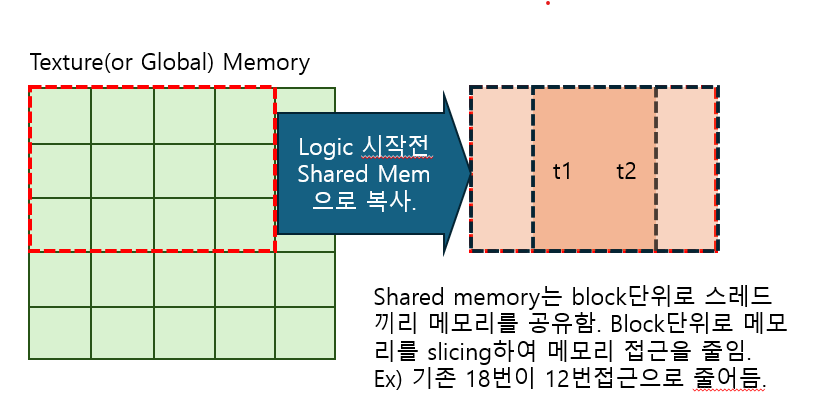
그래서 이 문제를 해결 하기 위해 SharedMemory에 데이터를 복사하여 처리를 하여 성능을 향상 시킨다. 이 기법은 tiled 기법 이라고도 부르고 캐싱이라고도 하는것 같다.
code
공유 메모리 크기는 FilterSize에 따른 동적 할당이 필요하므로 동적으로 할당하였다.
주의 할 점은 공유메모리에 데이터를 로드 하고 “syncthread()”를 호출하여 메모리 동기화를 해주어야한다.
const int TILE_DIMX = 32;
const int TILE_DIMY = 4;
dim3 grid(static_cast<unsigned int>(std::ceil(stAdtparam.width / TILE_DIMX)), static_cast<unsigned int>(std::ceil(stAdtparam.height / TILE_DIMY)));
dim3 block(TILE_DIMX, TILE_DIMY);
int halffiltersize = stAdtparam.halffiltersize;
int tile_width = TILE_DIMX + 2 * halffiltersize;
int tile_height = TILE_DIMY + 2 * halffiltersize;
size_t shared_mem_size = tile_width * tile_height * sizeof(unsigned char);
// 커널 호출 시 공유 메모리 크기 지정
Adt_SharedMemory << <grid, block, shared_mem_size >> > (
texAdtSrc,
cudaAdtDst,
cudaAdtRstX,
cudaAdtRstY
);
const int tile_width = blockDim.x + 2 * g_stAdtparam.halffiltersize;
const int tile_height = blockDim.y + 2 * g_stAdtparam.halffiltersize;
// 동적으로 할당된 공유 메모리를 가리킬 포인터
extern __shared__ unsigned char s_tile[];
// 1. 각 스레드의 글로벌/블록 내 인덱스 계산
int tx = threadIdx.x;
int ty = threadIdx.y;
int global_x = blockIdx.x * blockDim.x + tx;
int global_y = blockIdx.y * blockDim.y + ty;
// 이 스레드 블록이 처리할 데이터의 시작 위치 (글로벌 메모리 기준)
int start_x = blockIdx.x * blockDim.x - g_stAdtparam.halffiltersize;
int start_y = blockIdx.y * blockDim.y - g_stAdtparam.halffiltersize;
// 1. for문을 이용한 데이터 로딩 (1 스레드가 여러 픽셀 로드)
// 각 스레드가 tile_width * tile_width 크기의 공유 메모리를 채우기 위해 협력합니다.
for (int i = ty; i < tile_height; i += blockDim.y)
{
for (int j = tx; j < tile_width; j += blockDim.x)
{
int load_x = min(max(start_x + j, 0), g_stAdtparam.width - 1);
int load_y = min(max(start_y + i, 0), g_stAdtparam.height - 1);
s_tile[i * tile_width + j] = tex2D<unsigned char>(src, load_x, load_y);
}
}
// 3. 동기화
// 블록 내 모든 스레드가 공유 메모리에 데이터를 다 쓸 때까지 기다립니다.
__syncthreads();
// 4. 계산: 공유 메모리 사용
// 이제 모든 스레드는 공유 메모리에서 데이터를 읽어 평균을 계산합니다.
bool bPass = false;
float dAvg = 0;
int nDst = 0;
// 공유 메모리 내에서 필터링 수행
for (int y = ty; y < ty + g_stAdtparam.filterSize; ++y)
{
for (int x = tx; x < tx + g_stAdtparam.filterSize; ++x)
{
nDst = s_tile[y * tile_width + x];
dAvg += nDst;
}
}
dAvg /= (float)(g_stAdtparam.filterSize * g_stAdtparam.filterSize);
// 5. 임계값 처리 및 결과 쓰기
if (dAvg - g_stAdtparam.doublec < nSrc)
dst[global_y * g_stAdtparam.width + global_x] = 255;
else
dst[global_y * g_stAdtparam.width + global_x] = 0;

출처 - CUDA기반 GPU병렬처리 프로그래밍 (김덕수 저자(글))